Enterprise Management
How do you manage your IT infrastructure?
Trinity Solutions finds the clear answers to our clients complex questions. With years of experience helping clients run large enterprises, keeping their networks healthy, instantly finding problems with critical servers, tracking the status of their applications, and finding the best ways to manage thousands of desktops, we can show you what solutions work best for you.
Trinity Solutions specializes in providing the key solutions needed to keep the technology infrastructure running efficiently with the least downtime and minimal overhead on your staff. Every solution we provide is done with the motivation of saving you money and improving the service you provide to your clients.
How do you minimize your downtime while keeping your staff focused on growing your business?
Do these questions keep you up at night?
- Im not aware of what is happening in my environment right now
- Im not automatically notifying the right people of problems in my environment
- Im not automatically correcting problems that should be simple to solve
- Im being flooded with too much information
- Customers are finding problems before I am
- Im constantly "fire fighting"
- My NOC has to watch multiple screens just to see if everything is working
- I do not have any process for automatically identifying the root cause
- I do not know who is impacted from any given problem
- I do not know our current service level
- I do not know if Im meeting our SLA requirements
If so, your environment either needs an event management solution or your current solution is not adequate. Let's describe the key elements of an event management solution to help you avoid the common pit-falls experienced by many organizations. It is intended to serve as a vision for those trying to understand what event management is and where they fit within the common best practices.
Whether it is a server, a network, the OS, an application, or any other critical piece of your infrastructure, you need to know when it goes down, and preferably before it fails. Monitoring solutions must take into account the core needs of a company, and everything that supports that piece of infrastructure. After all, knowing that the server is up does not help if the network is down, the application has hung, or the database is out of space.
Trinity Solutions knows how to analyze a companies monitoring needs and find the solution that gets the necessary information into the right peoples hands quickly, before your customers are knocking on your door. We have implemented, extended, and customized monitoring solutions from commercial vendors and Custom Scripts. With this experience, we have built up a library of custom monitors that can expand your view into your infrastructure well beyond any out of the box installation that others provide.
Let's start with Event Management
Event management is the process of managing the flow of raw data so that it becomes useful information. For many organizations, this data identifies faults, performance problems, and security alerts. The raw feeds of information may arrive from networking equipment, server hardware, operating systems, databases, middle ware, and applications. Once received, it goes through a series of stages that convert this data from its raw form into alerts, tickets, and reports that provide an organization the information they need to quickly solve the important problems to increase availability and create value.
What Events Should be Received
An organization must find a balance between enough data to quickly identify the problems within an organization without having so much data that information can no longer be deciphered from the noise. They must resist the tendency to turn on all the prepackaged event sources to see what is available and instead focus on starting with a clean slate and building up a flow of events that are appropriate and valuable for that organization. There are several key steps that can guide an organization to finding this balance and building a solid base of data sources described below.
Identify Biggest Pain Points
When starting with a clean slate, an organization needs to first identify the items that provide the most value to add to the flow of events in the environment. This list should start with the most valuable items to that organization. To help build this list, ask yourself the following questions:
- What problems are frequently occurring?
- What key pieces of infrastructure affect the most users within the organization?
- What problems are most visible to our clients?
- What outages have the highest financial impact upon the organization?
- What problems are the most labor intensive to monitor using the existing methods?
- What problems go unnoticed for the longest periods of time, including service degradations that could be prevented from failing if detected early?
Every Event Adds Knowledge
When selecting events that should be received by the event management system, there should be a focus on ensuring every event adds some kind of value. If there is no additional value gained from an event, it should not be sent. Many events will identify the problem themselves and are obvious in the knowledge they provide. Others may help identify the root cause of a problem or provide information about the severity or duration of a problem. Some events may even provide an assurance of the environments health instead of indicate a problem. However, when events are received that do not even have the potential of requiring a response, they become noise that detracts from the issues requiring attention. By starting with a clean slate and adding events that are needed, there should be no noise events. Environments that already have too many noise events must tackle this problem with filtering at multiple levels to maximize the value from the event management system.
Filter Close to Source
When unnecessary events are sent in an environment, either because the environment already exists, or because the event sources may not be configurable, filtering is needed. This filtering will eliminate the need to process unneeded events and eliminate the noise that operators see when evaluating the status of the environment. When filters are configured, attention should be given to placing the filters as close to the source as possible. This reduces the load placed on the limited resources within an environment, including the network, proxy servers, the event processing engine, and external systems for ticketing and displaying the information.
Flow of Events
A company should be able to quickly identify what happens for any event that is received by their event management server. To simplify this process, many companies will standardize the flow of events so every event has some standardized processing with several locations that customized processing may occur. During the processing through this flow, the raw data in events may be filtered, correlated, and changed to convert them into information that is useful for people receiving the alerts or reviewing the reports. Most events in an environment will pass through every stage, or at least influence an event that does continue through the system. In environments where this does not happen, knowledge or value is lost, and problems may go unresolved. The following graphic shows a high level view of the flow of events.
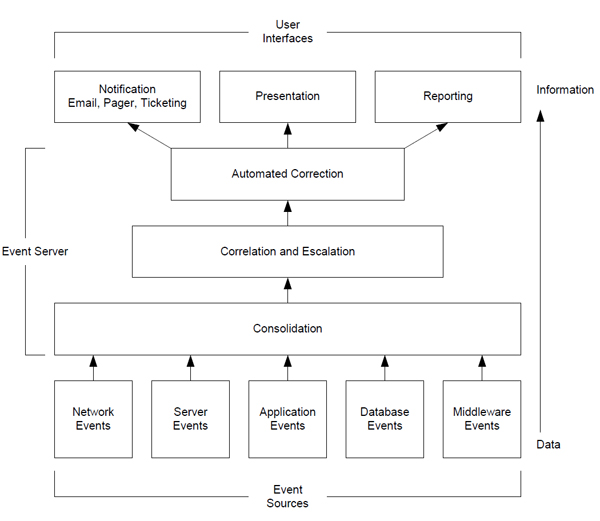
Event Sources
Events are received from multiple sources in many environments. These sources may include monitoring applications for servers and the network, SNMP events, log files, and directly from applications. They may report problems with an outage, performance alerts, or security issues. They should span all the systems used in the customers infrastructure, from the mainframe environment to the distributed systems. The selection of events sources is important since the more advanced and configurable the event sources are, the less modification and filtering of events at a higher level is needed. Placing the monitoring utilities near or on the monitored device will also reduce the impact on the customers infrastructure and permit filtering even closer to the event source. Customers should also standardize the configuration of their event sources and eliminate redundant event sources that provide no additional value. This will simplify the management of the environment and reduce the skill set needed to solve problems with the event management infrastructure.
Consolidation
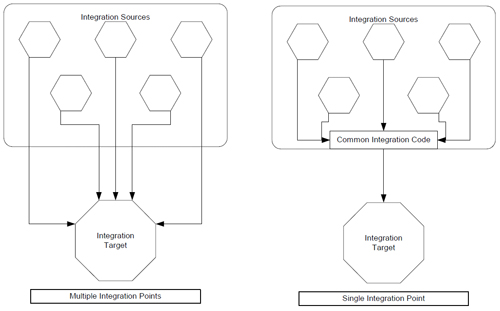
To efficiently manage the flow of events within an organization, all events need to be sent to a consolidated location. This enables all further steps to be performed on a single stream of information with a single configuration. It also enables efficient decision-making based off of information contained in multiple events. For sites that require high availability, multiple identical event servers may be located at different facilities with a method to synchronize the environments. Event sources would then send events to both servers, which may be a simple configuration or an external tool, like the SNMP trap exploders. Some environments may setup multiple consolidation servers to pre-process various event feeds, either from a specific site, or from a specific source of events. Other sites may setup various event servers for managing the flow of different types of events, such as one server for outages, another for performance monitoring, and a final one for security alerts. While these forms of division do not unnecessarily increase the complexity of the environment, effort should be taken to ensure that related events are consolidated and that there is one view of the problems within the environment. If possible, eliminating multiple integration points between the various parts of the event management environment will eliminate the need to make the same configuration in multiple places and monitor multiple failure points. Note that this does not apply when additional integration points are needed for load balancing or fault tolerance.
Processing - Correlation and Escalation
With the necessary data consolidated into one location, processing will be needed to turn this data into information. This processing begins by updating the event data into understandable values and brings it into a common format. Next, correlations between events are performed to determine the root cause, manage clearing events, and track the problems current state. Finally, escalation is performed to either clear or raise the severity of an event after a period of time or number of events has passed. The end result should be a system where only the actual problems are reported, without the noise of extraneous events.
Automated Correction
With the actual problem properly identified, the problem is ready to be solved. Many organizations will simply notify a person to manually solve the problem. However, most problems have easy solutions that can be automated. Those that do not may have an additional diagnostic performed while the problem is occurring to allow future debugging of an intermittent problem. The result of a corrective action is frequently logged or emailed for future analysis to aid in future problem prevention instead of rapid correction. A fail-safe is needed to ensure a notification is sent out for immediate response if a problem continues to occur after a corrective action has been performed. Organizations that do perform an automated correction will significantly reduce the number of notifications that require immediate attention and increase the service level since the delay of a person is eliminated.
Notification - Ticketing, Paging, and Email
The notification system is the first point a problem becomes visible to a user or administrator. A configuration problem with this system will be very apparent to end-users and can have a significant impact on service levels. By automating the ticketing, paging, and email, delays and mistakes can be avoided that would appear when manually performing these tasks. Notifications must utilize a method appropriate for the type of event and SLA. For example, paging an administrator should not occur for a preventative alert that will not become an outage for another day. Notifications should also be targeted to the minimum number of users to ensure users do not have to filter through problems that do not affect them. Over notifications will frequently result in notifications being ignored because of the "crying wolf" problem. Under notifications will result in an outage going unresolved. Therefore, a careful balance must be made that is best achieved by slowly adding notifications in the environment, just as event sources were slowly added.
Presentation
The presentation layer is actually optional for many clients depending on the design of their event management environment. Some clients will configure the environment to perform in a "lights out" configuration, where notifications are sent and the server is self-cleaning. Others require a method to view their problems to give a management level understanding of the current problems. This is also where organizations will perform a business impact analysis since outages will be displayed in each environment that they effect. These views are frequently organized by geographic region, affected applications, and support units. Many systems will allow "drill down" so specific areas are nested and can be opened from within high-level view. This "drill down" capability should allow the display of the actual alerts at the lowest levels and summarize the entire environment at the highest levels. This presentation layer should contain real-time data, which requires automated integration with the event server and configuration of the event server to automatically clear problems when they stop occurring.
Reporting
Reporting is an overlooked portion of many event management environments. Frequently data from events is cleared without any further analysis. This data can often be utilized for trending and other analysis to ensure the worst problems are reviewed to see if there is a way to prevent the problem or automate the solution. Service levels should be included in reports so management knows what service level agreements (SLA) are at risk of being breached. Clients may need reports to include charge back information so payment for the service can be gathered. Finally, a return on investment (ROI) analysis is also useful in a report so management is ensured they are receiving value from the solution they have implemented.
Reporting is frequently tailored to an individual client and is dependent on the needs of that client and the information available. To ensure information is available, a historical database of closed events should be maintained with the appropriate information attached to each event, including when the event was received, how long the event was opened, how it was closed, the severity of the event, type of event, and an appropriate description. Many clients will tie in information from their ticketing solution, however, if this is the sole source of information, care should be taken to ensure enough information is available at that level. Finally, reports should be located where they are useful to the client. This frequently involves placing the reports on a web site or sending them by email.
Common Mistakes
This section will attempt to identify common mistakes and what problems will result so that you can avoid making these same mistakes.
Too Many Events
Many clients will try to get a quick return on their event management solution by turning on all events from all sources at once. The result is frequently too much data with a significant amount of noise events and many events that do not apply to the client. When notifications are made from this unformatted data, over alerting is a frequent problem, and the value of the event management solution significantly decreases. The best practices method to adding events to the environment is by identifying the problems that need to be solved and add only the events needed for each problem. This ensures that administrators are notified of problems that are important to them and that noise events are kept to a minimum.
Too Few Events
To accurately identify problems and their root cause, there needs to be enough information being sent to the event server. For client specific applications, this will frequently involve a custom monitor. The approach should always begin by looking at how the end users see the environment and where the failure points are within the environment instead of looking at what prepackaged monitors are available. An effort to identify the potential problems with a root cause analysis is also needed to more effectively deploy resources to solve a problem and automate the solutions to common problems. This frequently involves the correlation of multiple alerts, such as an alert that a web server cannot be reached should be correlated with a router outage or host down so that the proper response can be taken. By ensuring that each monitor is needed to detect a specific problem, the common mistake of too many events is also avoided.
Poorly Defined Severities
Many environments will rely on the severities that come standard with many event sources. These severities may not map appropriately to their environment and will result in an event management environment where it is not clear what problems require immediate attention. This will also interfere with notification systems that rely on severity for determine the appropriate notification method. The solution is to create a definition for each severity that is tied to the severity of the outage, required response time for the SLA, appropriate notification method, and escalation process. Once this is created, every event severity should be assigned according to what severity the problem is that the event represents. Clearing events may have their own severity and events that require correlation with another event to identify a problem should be sent in with an informational severity. This simplifies the design of notification systems, enables a quick assessment of the state of the environment from the presentation layer, and allows efficient tracking of SLAs.
No Standardized Processing
Ensuring that every event contains a clear path through the event management system will help reduce the effort to maintain the system. When a system is difficult to understand or follow, two costs will be incurred: the cost of making mistakes in the processing of events, and the cost of personnel that attempt to understand and configure the path of each event. The standard path in an event management environment should be an end-to-end description that includes the various steps of event processing, a method to close the event, notification, presentation, and reporting. There will frequently be locations where custom processing may be added between various steps. This is frequently seen for custom correlation or corrective actions since they are different for each type of event. However, most of the steps should be made as generic and reusable as possible so new events require the minimum amount of work and the flow of events is clear and understandable to outside users. Additionally, custom configuration should be performed in common locations so the number of places that needs to be researched for any given event is minimized.
An environment that utilizes standardized processing of events may have the following elements:
- Common methods to send events from various sources
- Common processing and a single location to filter events as they are received
- One common method for all clearing events (either with a different type of event, a clearing flag within the event, or a different severity for the event)
- One location to processing correlations according to a configuration file
- Common method for processing all duplicate events
- One location to run all corrective actions based on a configuration file
- One location to perform all notifications based on a configuration file for email and paging and a list of approved events for ticketing
- One location to perform all integrations into presentation systems
The result is a few configuration locations and a standard default path for all events that is easy to manage.
Over Notification
Commonly related to the problem of sending too many events is sending too many notifications. This may result from:
- Sending notifications for noise events that are not really problems or have no effect for the client.
- Sending alerts to a large group of people instead of targeting alerts to only the people that need to respond to the problem.
- Sending a page for a problem when an email or less intrusive alert would have been appropriate.
The solution is similar to the method of bringing in events slowly. Notifications must be slowly added to the environment, with each notification being important to the environment. In addition, as each event is added to the environment, some action, which is frequently a notification, should be defined and created. This ensures that every event that needs a notification has one and only those people that need to receive a notification receive one. This eliminates the two problems from over and under notification: ignoring alerts because of the "crying wolf" problem and missing problems that need a response.
No Process to Close Every Event
Many clients will focus on getting the right events into their environment and completely ignore the need to close these events. Frequently the task is left to administrators that forget to perform the task, or the ticketing system that may not have a ticket for every event. At the very minimum, a maximum age for events needs to be identified for the environment. Once an event exceeds this age, a process to close the event and update ticketing and presentation systems. There should also be a method of reporting these expired alerts and a notification should be sent to the person normally responsible for closing the alert. Additionally, as new events are added to the environment, a method for clearing the event should be defined. For example, a method of monitoring a process or disk space on a server should report when the process or disk has returned to normal operation with a clearing event. These clearing events are important for tracking SLAs and having a clear view of the current environment. The problem with not having a process to close an event is that there will be a slow build-up of events over time, continuously degrading performance and requiring more resources. Additionally, correlation and notification systems may not work properly if they believe a problem is still occurring after an administrator has corrected the problem.
Forgetting to "Sell" the Solution
Event management involves monitoring and gathering data that may be considered intrusive to the people providing the data and receiving the notifications. For an effective deployment of event management, time must be spent selling the solution to the affected users. Attention must be given to getting "buy in" from these users and finding value that they will receive from the solution. It is much easier to implement a solution when the impacted users see the value and are requesting the solution to be implemented in their environment. In environments where this does not happen, many organizations will fail to receive input from the end users and have difficulty deploying the solution on the end users systems.
Ending the Project After Implementation
An event management project has a life cycle just like any other project and requires long-term maintenance and support. Even after deploying the solution, it will need to expand as more events and knowledge are added and grow with the company. The people that perform this task may not need the skill of an architect, but the skills of an implementer or developer will be very useful. Failure to do so will result in the event management system slowly degrading over time and becoming less useful for the companies current problems. This is frequently the reason many organizations have "console creep" in an operations center, systems are not integrated and new systems are added to provide functionality lacking from another. By continuing the event management project over the long term, consoles will be consolidated and features will be added to a single console that reports only the information relevant that operations center. Additionally, automation and prevention may decrease the number of problems that require human intervention over time, though expansion of the event sources will tend to increase the total number of events received by the event server.
Improper Staffing of Implementation Team
Many clients will attempt to staff an event management solution with personnel that are not familiar with the solution or the event management methodology. This frequently results in a slow deployment with many problems that are visible to the end users, and the implementation of a tool and not a solution that provides value to the customers environment. People implementing an event management solution must have the people skills to gather the information needed and sell the solution, understand the high level structure of the solution and know the reasoning behind the architecture, and have a working knowledge of the programming language and products involved in the various integrations and steps of the event management environment.
Resulting Solution
The resulting solution from these best practices should be an event management solution with these properties:
- Receives events from multiple sources
- Filters out noise events
- Quickly identifies root cause problems
- Automatically updated with the current status of the environment
- Integrated with the notification, presentation, and reporting systems
- Easy to manage
- Scales with the environment
This helps organizations realize the value of an event management solution, which is to process alerts automatically so that administrators can avoid the task of manual monitoring and instead focus on providing new services for an organization, only worrying about fixing problems when they exist.
Monitoring Methodology
Trinity Solutions has developed a standard monitoring methodology that has been proven successful. Critical success factors for the monitoring methodology consist of:
- Working with the application groups to determine monitoring needs.
- Listing at least 5 critical elements to monitor.
- Understanding all critical points of failure that will need monitored.
- Web Page or commercial solutions as the focal point for events.
- Write Rules to handle event notification.
- Gathering the notification information (paging, email, etc..)
- Develop standard email groups so a group name is passed, not member names. These groups will be maintained and owned by the application owners. These groups will contain the names of their on call personnel for critical events and email addresses for warning events.
- Communicate all Level 1 and Level 2 events with helpdesk.
- Integrate critical events into ticketing system for escalation and RCA.
Trinity Solutions and the monitoring team will meet with each application development group to determine the criterion for application monitoring. The monitoring team will develop a good rapport with each group giving them the understanding that they are the application experts.

